Resultaten publiceren
In dit hoofdstuk bespreken we het publiceren van resultaten naar de webviewer.
Publiceren naar de webviewer is mogelijk wanneer de volgende stappen zijn afgerond:
- Simulaties compleet
- Resultaatbestanden gekopieerd naar de stochastenmap
- Resultaatbestanden uitgelezen naar de database en/of csv-bestanden (2D)
- Resultaten nabewerkt tot herhalingstijden
Wanneer al deze acties compleet zijn, wordt de knop ‘Publiceren’ op het tabblad ‘Simulaties’ uitvoerbaar gemaakt (enabled).
Na klikken op deze button verschijnt het volgende formulier:
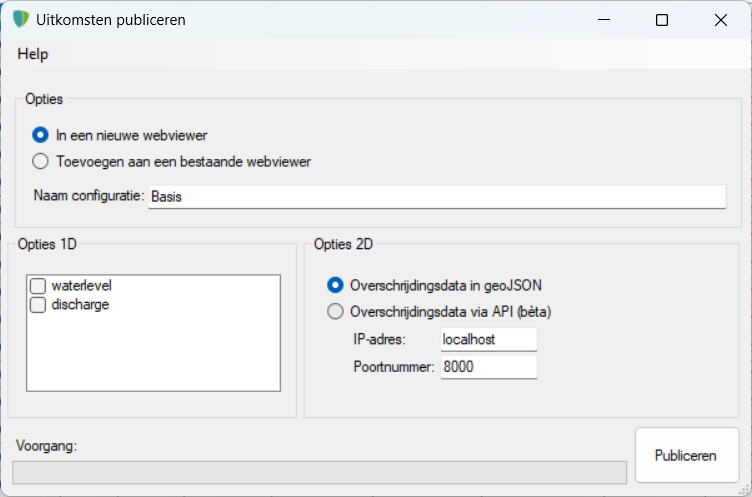
- Opties: Kies hier of voor de resultaten een nieuwe webviewer moet worden gegenereerd, of dat de resultaten moeten worden toegevoegd aan een bestaande webviewer.
- Naam configuratie: geef hier een unieke naam op voor de huidige stochastenanalyse
- Opties1D: Kies hier welke modelparameters moeten worden gepubliceerd in de viewer
- Opties2D: Kies hier of alle resultaten in het memory van de viewer worden opgenomen (handig voor kleine modellen) of dat de overschrijdingsdata dusdanig groot is dat hij vanuit de viewer via een API moet worden bevraagd
Hieronder werken we de verschillende opties verder uit:
- Opties:
- De standaardoptie is om de huidige resultaten in een nieuwe viewer te publiceren. Maar soms is het wenselijk om de uitkomsten te kunnen vergelijken met andere stochastenanalyse; bijvoorbeeld als er meerdere duren in het spel zijn.
Bij het klikken op de optie “Toevoegen aan een bestaande webviewer” wordt gevraagd de map met bestaande webviewer te selecteren. Kies dan de map waarin index.html staat.
Zorg bij het geven van een naam dat die kort en bondig is en uniek is ten opzicht van de namen van de andere analyses in de viewer. De naam zie je straks terug in de legenda van de overschrijdingsgrafieken.
- Opties1D:
- Hier verschijnt een lijst met alle unieke parameters die in de herhalingstijden-tabel van de database te vinden zijn. Selecteer welke parameters in de viewer moeten worden gepubliceerd.
- Opties2D:
- Deze optie is nog in ontwikkeling, maar de aanleiding is dat zeer grote 2D-modellen niet in de Browser Cache passen. Voor grote modellen is het niet raadzaam alle data in het geheugen van de viewer te laden en moeten we dus werken via een API. Als vuistregel hanteren we dat modellen met meer dan 200 duizend rekencellen beter via de API ontsloten kunnen worden.
Bij het ontsluiten via een API al De Nieuwe Stochastentool de overschrijdingsdata wegschrijven naar een SQLite-database en dan automatisch een kleine server starten. Die server levert op aanvraag van de browser de overschrijdingsdata van een gegeven 2D-cel.